D-index
Overview
D-index combines the hash partitioning method (i.e., excluded middle partitioning) and the pivot mapping technique. The basic idea of the D-Index is to create a multilevel storage and retrieval structure that uses several ρ-split functions, one for each level, to create buckets for storing objects. On the first level, we use a ρ-split function for separating objects of the whole data set. The ρ-split function can partition the dataset into three buckets, i.e., bucket 0, bucket 1, and exclusion bucket, as shown in Fig. 1. For any other level, objects mapped to the exclusion bucket of the previous level are the candidates in separable buckets of this level. For example, in Fig. 1, objects in exclusion bucket '-' (i.e., o3, o5, o9) at level 1 are candidates to be divided in level 2. Finally, the exclusion bucket of the last level forms the exclusion bucket of the whole D-index. Here, the ρ-split functions of individual levels use the same ρ. Fig. 1 gives an example of D-index, where a ρ-split function based on o7 is used at level 1, and a ρ-split function based on o3 is used at level 2.
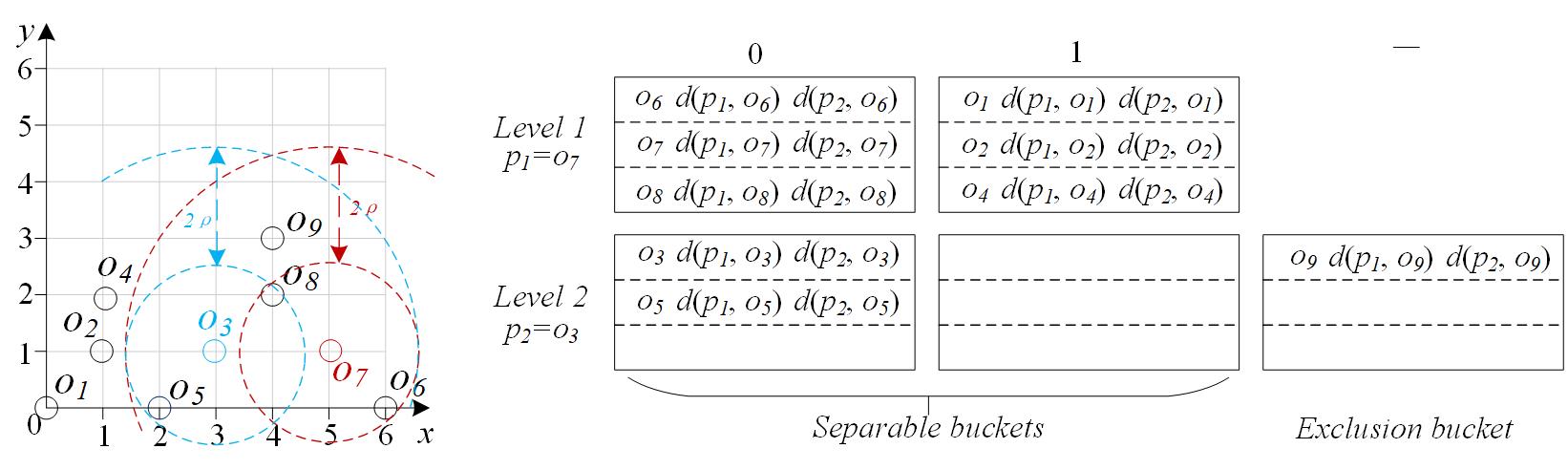
Fig. 1 The example of D-index
Code Usage
The code is provided by the authors of D-index, and thus, is not released here.